Table of Contents
ToggleEvery successful analytics and artificial intelligence project starts with one critical step: Data Preprocessing in Big Data Analytics. Before organizations can discover meaningful insights or train accurate machine learning models, raw data must be cleaned, organized, transformed, and prepared. This guide explains how data preprocessing turns complex datasets into reliable business assets that support smarter decisions and better outcomes.
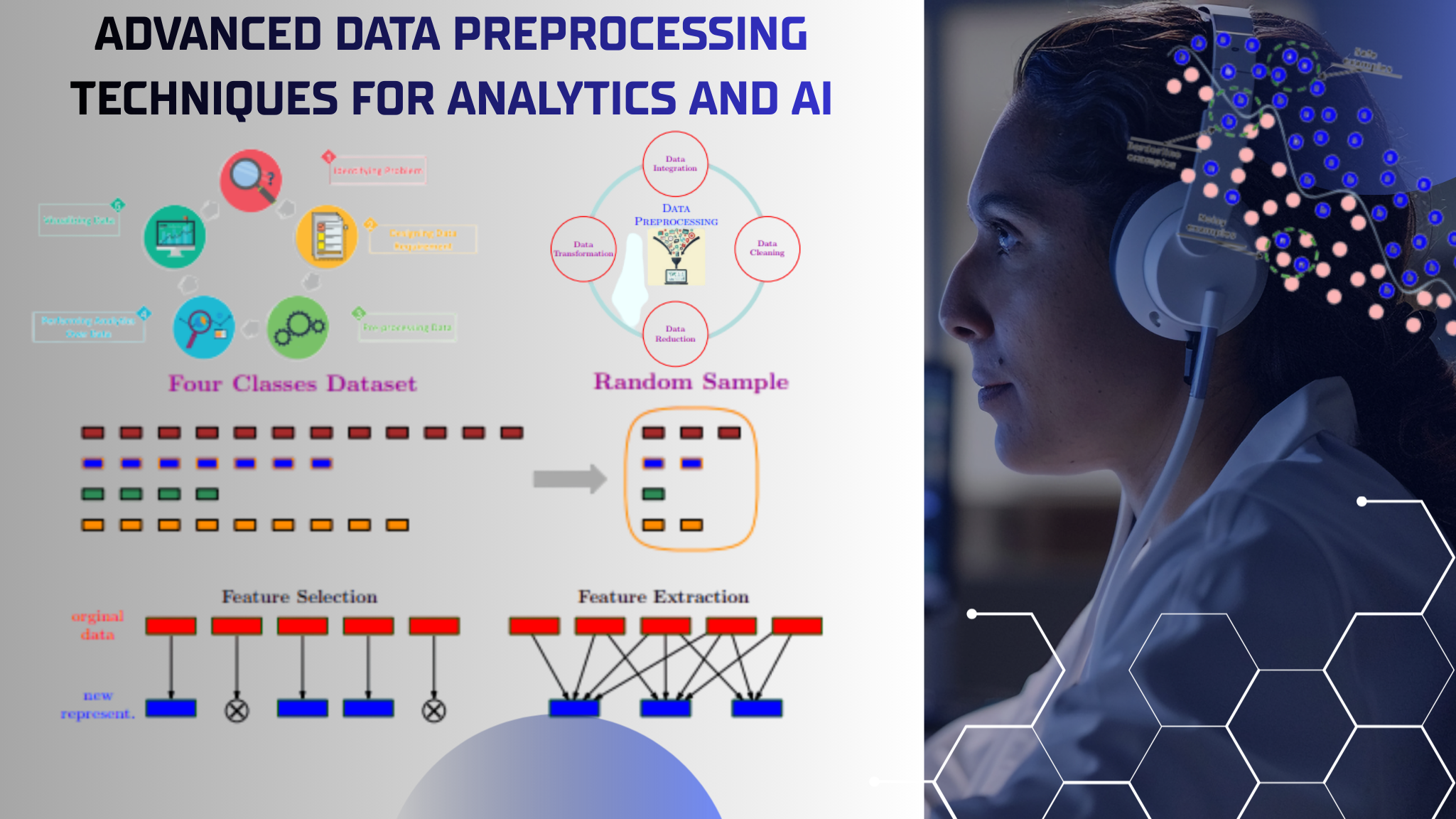
Data Preprocessing in Big Data Analytics: Foundations, Techniques, and Strategic Importance
Introduction:
Data has become one of the most valuable resources in the modern business world. Organizations collect information from websites, mobile applications, social media platforms, sensors, cloud systems, and customer interactions every second. However, collecting data alone does not create value. Raw information often contains errors, inconsistencies, duplicates, missing values, and irrelevant records that can negatively affect analytics results.
This is where Data Preprocessing in Big Data Analytics becomes essential. It acts as the foundation for successful analytics, artificial intelligence, and machine learning initiatives. Without proper preprocessing, even advanced algorithms struggle to generate accurate outcomes.
Let me explain this in the clearest, simplest terms.
Imagine building a house on weak ground. No matter how beautiful the structure looks, it will eventually develop problems. Data works in the same way. If the underlying data is poor, the resulting insights will also be unreliable.
Organizations that invest in robust preprocessing practices gain more accurate predictions, stronger business intelligence, improved operational efficiency, and better strategic decision-making.
What Is Data Preprocessing in Big Data Analytics?
Data preprocessing refers to the process of converting raw, unstructured, incomplete, or inconsistent data into a clean and usable format for analysis.
In big data environments, preprocessing becomes more challenging because organizations handle massive volumes of information from multiple sources simultaneously. Data arrives in different formats, structures, and speeds, making preparation a critical stage before analysis begins.
The primary objective is to improve data quality and ensure that analytics systems receive reliable information for processing.
Data preprocessing commonly includes:
- Data collection
- Data cleaning
- Data integration
- Data transformation
- Data reduction
- Feature engineering
- Data validation
- Data normalization
Together, these activities create a strong foundation for advanced analytics.
Why Data Preprocessing Matters More Than Ever:
Modern businesses depend on data-driven decisions. Whether a company wants to predict customer behavior, detect fraud, improve supply chains, or personalize marketing campaigns, the quality of the data directly impacts success.
A small error in a dataset can produce significant consequences. For example, an e-commerce company using inaccurate customer data may recommend irrelevant products, reducing customer satisfaction and sales performance.
Proper preprocessing helps organizations:
- Improve data accuracy
- Reduce operational risks
- Increase machine learning performance
- Enhance business intelligence reporting
- Minimize analytical errors
- Strengthen regulatory compliance
Companies that prioritize preprocessing often achieve faster and more reliable results from their analytics investments.
Understanding Data Collection and Data Provenance:
The preprocessing journey begins with data collection.
Organizations gather information from multiple sources including:
- Enterprise databases
- CRM systems
- Social media platforms
- IoT devices
- Cloud applications
- APIs
- Customer transactions
Each source introduces different challenges and quality concerns.
An equally important concept is data provenance. Data provenance tracks where data originates, how it moves through systems, and what transformations occur throughout its lifecycle.
For industries such as healthcare, banking, and insurance, maintaining provenance records helps support transparency, auditing, compliance, and trust.
When organizations understand their data origins, they can better evaluate reliability and accuracy.
Common Data Quality Issues in Big Data Analytics:
Poor-quality data remains one of the biggest obstacles in modern analytics.
Several issues frequently appear in large datasets:
Missing Values:
Data may be incomplete due to system failures, human mistakes, or unavailable information.
Duplicate Records:
The same information may be stored multiple times across systems, creating inconsistencies.
Inconsistent Formats:
Dates, currencies, measurement units, and naming conventions may differ between data sources.
Noise:
Random errors and irrelevant information can distort analytical results.
Outliers:
Extreme values may significantly influence statistical calculations and machine learning models.
Identifying and resolving these issues is a crucial preprocessing responsibility.
How Is Missing Data Handled Effectively?:
Missing values are unavoidable in most real-world datasets.
Several strategies help address missing information:
Record Removal:
Rows containing missing values can be removed when the amount of missing data is minimal.
Mean and Median Imputation:
Missing numerical values are replaced with average or median values.
Predictive Imputation:
Machine learning models estimate missing information using existing relationships in the dataset.
Advanced Statistical Methods:
Sophisticated techniques preserve data integrity while minimizing information loss.
Selecting the right method depends on business objectives, dataset size, and data distribution.
Managing Noise and Outliers in Analytics:
Noise and outliers can significantly affect analytical performance.
For example, if most customer purchases range between $50 and $500 but one record shows a purchase of $500,000, analysts must determine whether the value represents an error or a legitimate transaction.
Several techniques help identify anomalies:
- Z-score analysis
- Interquartile range analysis
- Clustering methods
- Machine learning-based anomaly detection
- Visualization techniques
In fraud detection systems, unusual patterns often represent valuable business intelligence rather than errors. Therefore, context always matters.
What Role Does Exploratory Data Analysis Play?:
Exploratory Data Analysis, commonly called EDA, helps analysts understand datasets before applying transformations or building models.
EDA allows teams to discover:
- Patterns
- Trends
- Correlations
- Data distributions
- Outliers
- Missing values
Practical EDA techniques include:
- Histograms
- Box plots
- Scatter plots
- Correlation matrices
- Summary statistics
By understanding the data first, organizations can make better preprocessing decisions later.
Data Cleaning Techniques for Better Accuracy:
Data cleaning represents one of the most important stages of preprocessing.
The goal is to eliminate inaccuracies and improve consistency.
Common cleaning activities include:
Data Deduplication:
Removing repeated records across systems.
Data Validation:
Verifying that entries follow predefined rules.
Standardization:
Converting values into consistent formats.
Error Correction:
Fixing inaccurate or corrupted records.
Clean datasets provide stronger foundations for machine learning and business analytics.
How Does Data Integration Work in Big Data Environments?:
Modern organizations rarely store all information in a single system.
Data integration combines multiple sources into a unified dataset.
Successful integration requires:
- Schema alignment
- Data mapping
- Entity matching
- Conflict resolution
- Metadata management
For example, customer information may exist in sales, marketing, and support systems. Integration creates a complete customer view that enables more accurate analytics.
Data Transformation and Its Business Value:
Data transformation converts information into formats suitable for analysis.
Popular transformation techniques include:
- Aggregation
- Normalization
- Encoding
- Scaling
- Mathematical transformation
For example, highly skewed financial data may require logarithmic transformation to improve analytical performance.
Transformation improves compatibility between data and machine learning algorithms.
Encoding Categorical Data for Machine Learning:
Many machine learning models require numerical input.
Categorical information such as product categories or customer segments must therefore be converted into numbers.
Popular encoding methods include:
One-Hot Encoding:
Creates binary variables for each category.
Label Encoding:
Assigns numerical values to categories.
Target Encoding:
Uses target variable statistics to represent categories.
Selecting the correct encoding method helps improve model accuracy while reducing bias.
Feature Engineering and Feature Selection:
Feature engineering is often considered the most valuable preprocessing activity.
It involves creating meaningful variables that improve model performance.
Examples include:
- Customer lifetime value
- Purchase frequency
- Average transaction amount
- Seasonal behavior indicators
Feature selection focuses on retaining only the most useful variables.
Benefits include:
- Reduced complexity
- Faster processing
- Improved interpretability
- Lower risk of overfitting
Effective feature engineering often determines whether a machine learning project succeeds or fails.
Dimensionality Reduction and PCA:
As datasets grow larger, they often contain hundreds or thousands of variables.
Excessive dimensions create computational challenges and reduce model efficiency.
Dimensionality reduction addresses this issue by simplifying datasets while preserving critical information.
One of the most popular approaches is:
Principal Component Analysis (PCA):
PCA transforms correlated variables into smaller sets of independent components.
Benefits include:
- Faster computation
- Better visualization
- Reduced storage requirements
- Improved model performance
Many organizations use PCA to manage large-scale analytical workloads efficiently.
Scaling and Normalization in Machine Learning:
Machine learning algorithms often perform better when variables share similar scales.
Common scaling methods include:
Min-Max Scaling:
Transforms values into a range between 0 and 1.
Z-Score Normalization:
Centers data around the mean and standard deviation.
Benefits include:
- Faster model training
- Improved convergence
- Better prediction accuracy
- Enhanced algorithm stability
Scaling becomes especially important for distance-based algorithms.
Addressing Class Imbalance in Data:
Class imbalance occurs when one category significantly outnumbers another.
For example, fraudulent transactions may represent only a tiny fraction of all transactions.
Several preprocessing methods help balance datasets:
- Oversampling
- Undersampling
- Synthetic data generation
- Weighted algorithms
Balanced datasets improve fairness, reliability, and predictive performance.
The Importance of Data Governance and Metadata:
As organizations scale analytics operations, governance becomes increasingly important.
Metadata provides essential information about:
- Data structure
- Ownership
- Processing history
- Transformation rules
Strong governance frameworks support:
- Regulatory compliance
- Data quality control
- Security management
- Transparency
Organizations that maintain robust governance practices often achieve more trustworthy analytical outcomes.
Future Trends in Data Preprocessing:
The future of preprocessing is becoming increasingly automated.
Emerging technologies include:
- Automated machine learning platforms
- AI-powered data cleaning
- Real-time preprocessing pipelines
- Intelligent anomaly detection
- Automated feature engineering
These innovations help organizations process larger datasets while reducing manual effort.
Despite automation advances, human expertise remains essential for interpreting results and making strategic decisions.
Why Businesses Cannot Ignore Data Preprocessing:
Many organizations invest heavily in analytics platforms but underestimate preprocessing requirements.
Industry studies consistently show that data professionals spend a significant portion of their time preparing data rather than building models.
This investment is worthwhile because preprocessing delivers:
- Higher-quality insights
- Better machine learning outcomes
- Reduced business risks
- Faster decision-making
- Greater return on analytics investments
Organizations that prioritize preprocessing create stronger competitive advantages in data-driven markets.
Conclusion:
At worldstan.com, we believe that Data Preprocessing in Big Data Analytics is the hidden engine behind every successful analytics, artificial intelligence, and machine learning initiative. Raw data alone has little value until it is cleaned, transformed, validated, and structured into a format that supports meaningful analysis. Organizations that invest in preprocessing gain more accurate insights, stronger predictive capabilities, and greater confidence in their decision-making processes. As data volumes continue to expand across industries, the ability to prepare information effectively will separate high-performing organizations from those struggling with unreliable analytics. The future belongs to businesses that treat data preprocessing not as a technical task, but as a strategic advantage.